Publications
Publications in reversed chronological order.
2026
-
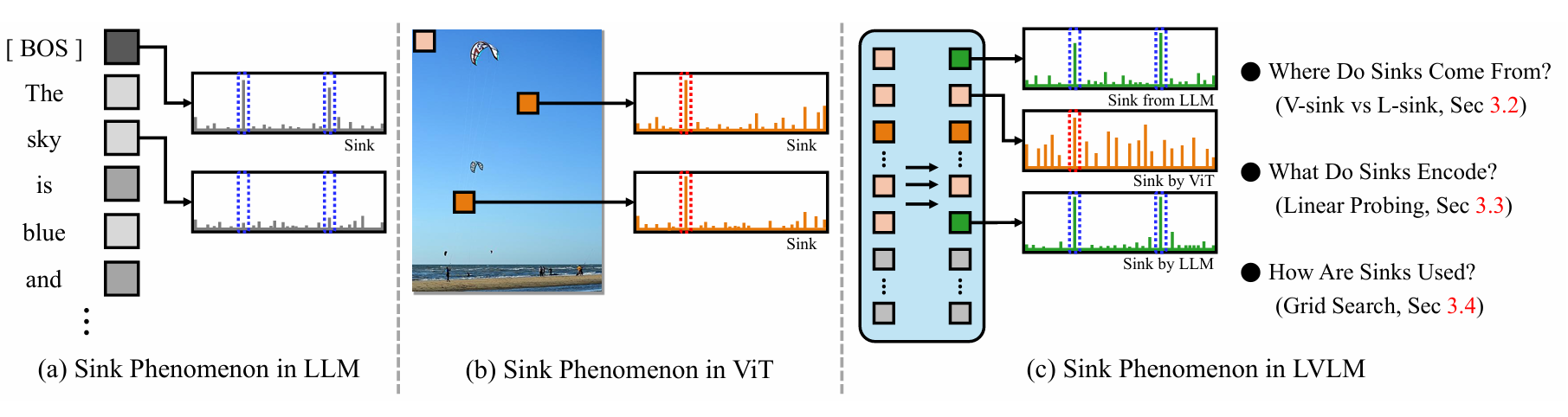 When Sinks Help or Hurt: Unified Framework for Attention Sink in Large Vision-Language ModelsJiho Choi, Jaemin Kim, Sanghwan Kim, and 2 more authorsUnder Review, 2026
When Sinks Help or Hurt: Unified Framework for Attention Sink in Large Vision-Language ModelsJiho Choi, Jaemin Kim, Sanghwan Kim, and 2 more authorsUnder Review, 2026Attention sinks are defined as tokens that attract disproportionate attention. While these have been studied in single modality transformers, their cross-modal impact in Large Vision-Language Models (LVLM) remains largely unexplored: are they redundant artifacts or essential global priors? This paper first categorizes visual sinks into two distinct categories: ViT-emerged sinks (V-sinks), which propagate from the vision encoder, and LLM-emerged sinks (L-sinks), which arise within deep LLM layers. Based on the new definition, our analysis reveals a fundamental performance trade-off: while sinks effectively encode global scene-level priors, their dominance can suppress the fine-grained visual evidence required for local perception. Furthermore, we identify specific functional layers where modulating these sinks most significantly impacts downstream performance. To leverage these insights, we propose Layer-wise Sink Gating (LSG), a lightweight, plug-and-play module that dynamically scales the attention contributions of V-sink and the rest visual tokens. LSG is trained via standard next-token prediction, requiring no task-specific supervision while keeping the LVLM backbone frozen. In most layers, LSG yields improvements on representative multimodal benchmarks, effectively balancing global reasoning and precise local evidence.
@article{choi2026sink, title = {When Sinks Help or Hurt: Unified Framework for Attention Sink in Large Vision-Language Models}, author = {Choi, Jiho and Kim, Jaemin and Kim, Sanghwan and Hong, Seunghoon and Park, Jin-Hwi}, journal = {Under Review}, year = {2026}, } -
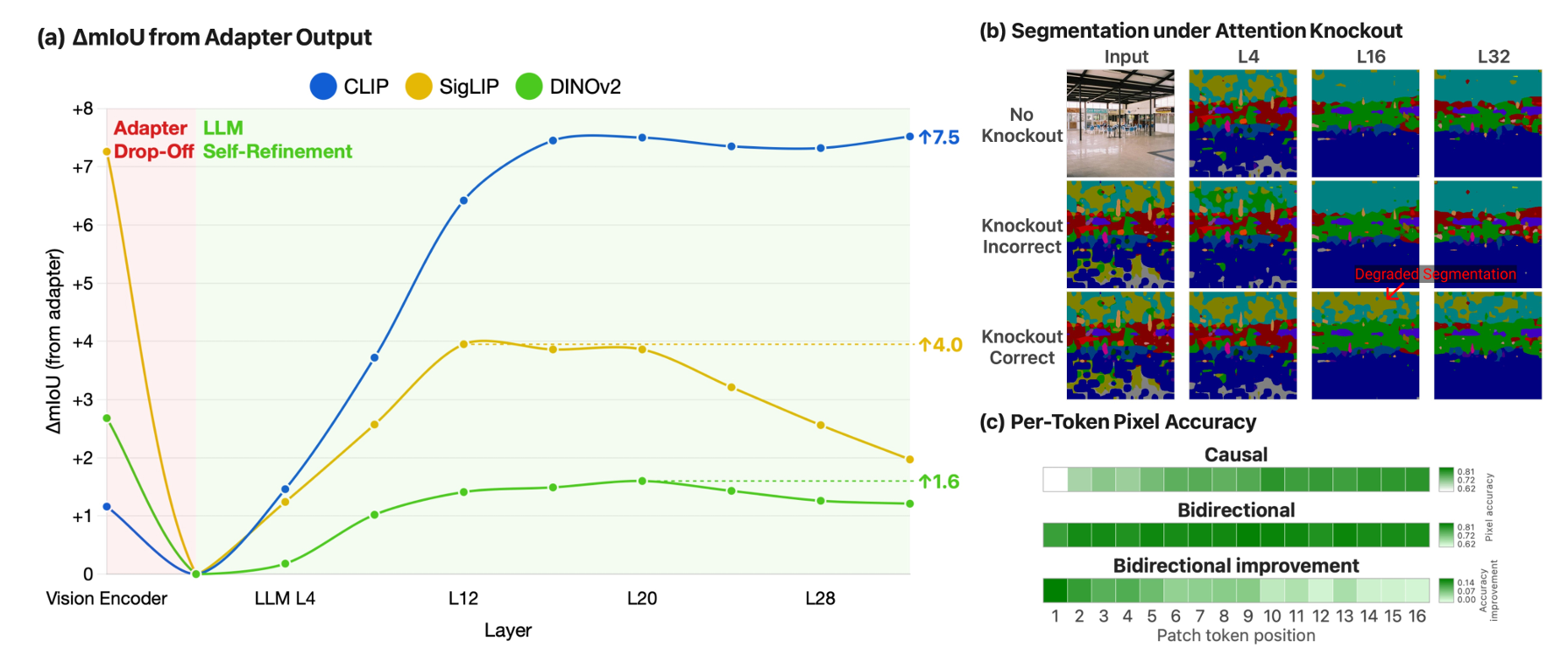 From Drop-off to Recovery: A Mechanistic Analysis of Segmentation in MLLMsBoyong Wu, Sanghwan Kim, and Zeynep AkataUnder Review, 2026
From Drop-off to Recovery: A Mechanistic Analysis of Segmentation in MLLMsBoyong Wu, Sanghwan Kim, and Zeynep AkataUnder Review, 2026Multimodal Large Language Models (MLLMs) are increasingly applied to pixel-level vision tasks, yet their intrinsic capacity for spatial understanding remains poorly understood. We investigate segmentation capacity through a layerwise linear probing evaluation across the entire MLLM pipeline: vision encoder, adapter, and LLM. We further conduct an intervention based attention knockout analysis to test whether cross-token attention progressively refines visual representations, and an evaluation of bidirectional attention among image tokens on spatial consistency. Our analysis reveals that the adapter introduces a segmentation representation drop-off, but LLM layers progressively recover through attention-mediated refinement, where correctly classified tokens steer misclassified neighbors toward the correct label. At early image token positions, this recovery is bounded by causal attention, which bidirectional attention among image tokens alleviates. These findings provide a mechanistic account of how MLLMs process visual information for segmentation, informing the design of future segmentation-capable models.
@article{wu2026drop, title = {From Drop-off to Recovery: A Mechanistic Analysis of Segmentation in MLLMs}, author = {Wu, Boyong and Kim, Sanghwan and Akata, Zeynep}, journal = {Under Review}, year = {2026}, } -
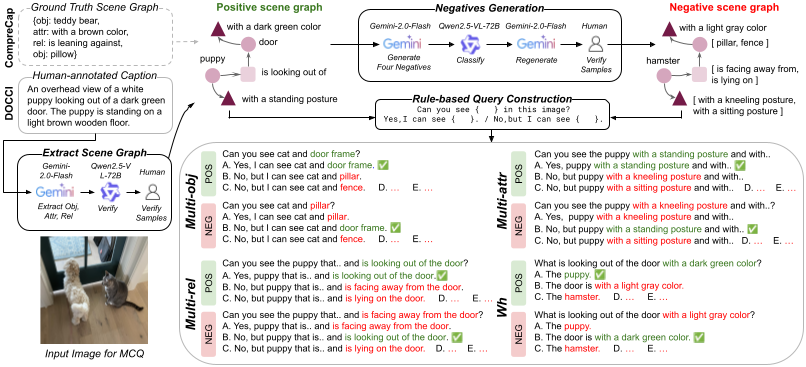 FINER: MLLMs Hallucinate under Fine-grained Negative QueriesRui Xiao, Sanghwan Kim, Yongqin Xian, and 2 more authorsCVPR, 2026
FINER: MLLMs Hallucinate under Fine-grained Negative QueriesRui Xiao, Sanghwan Kim, Yongqin Xian, and 2 more authorsCVPR, 2026Multimodal large language models (MLLMs) struggle with hallucinations, particularly with fine-grained queries, a challenge underrepresented by existing benchmarks that focus on coarse image-related questions. We introduce FIne-grained NEgative queRies (FINER), alongside two benchmarks: FINER-CompreCap and FINER-DOCCI. Using FINER, we analyze hallucinations across four settings: multi-object, multi-attribute, multi-relation, and “what” questions. Our benchmarks reveal that MLLMs hallucinate when fine-grained mismatches co-occur with genuinely present elements in the image. To address this, we propose FINER-Tuning, leveraging Direct Preference Optimization (DPO) on FINER-inspired data. Finetuning four frontier MLLMs with FINER-Tuning yields up to 24.2% gains (InternVL3.5-14B) on hallucinations from our benchmarks, while simultaneously improving performance on eight existing hallucination suites, and enhancing general multimodal capabilities across six benchmarks.
@article{xiao2026finer, title = {FINER: MLLMs Hallucinate under Fine-grained Negative Queries}, author = {Xiao, Rui and Kim, Sanghwan and Xian, Yongqin and Akata, Zeynep and Alaniz, Stephan}, journal = {CVPR}, year = {2026}, } -
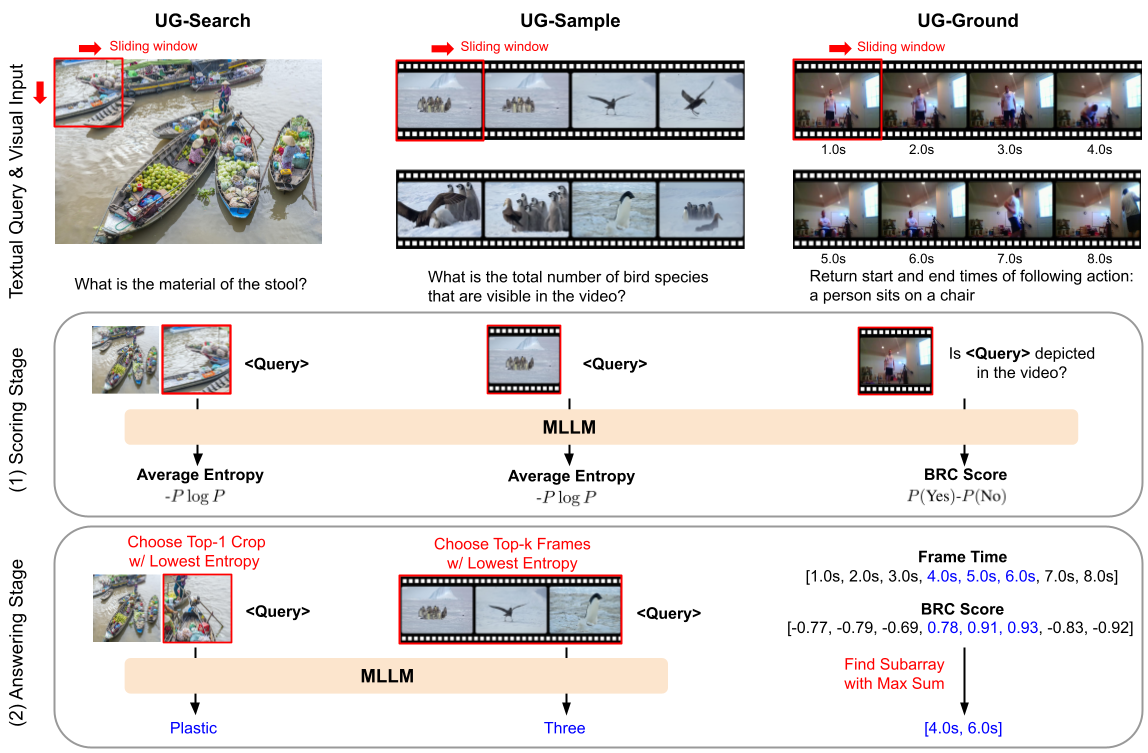 Training-free Uncertainty Guidance for Complex Visual Tasks with MLLMsSanghwan Kim, Rui Xiao, Stephan Alaniz, and 2 more authorsUnder Review, 2026
Training-free Uncertainty Guidance for Complex Visual Tasks with MLLMsSanghwan Kim, Rui Xiao, Stephan Alaniz, and 2 more authorsUnder Review, 2026Multimodal Large Language Models (MLLMs) often struggle with fine-grained perception, such as identifying small objects in high-resolution images or detecting key moments in long videos. Existing methods typically rely on complex, task-specific fine-tuning, which reduces generalizability and increases system complexity. In this work, we propose an effective, training-free framework that uses an MLLM’s intrinsic uncertainty as proactive guidance. Our core insight is that a model’s uncertainty decreases when provided with relevant visual information. We introduce a unified mechanism that scores candidate visual inputs by response uncertainty, enabling the model to autonomously focus on the most informative data. We apply this simple principle to three challenging visual tasks: Visual Search, Long Video Understanding, and Temporal Grounding, allowing off-the-shelf MLLMs to achieve performance competitive with specialized, fine-tuned systems. Our results demonstrate that leveraging intrinsic uncertainty is a powerful strategy for improving fine-grained multimodal performance.
@article{kim2025training, title = {Training-free Uncertainty Guidance for Complex Visual Tasks with MLLMs}, author = {Kim, Sanghwan and Xiao, Rui and Alaniz, Stephan and Xian, Yongqin and Akata, Zeynep}, journal = {Under Review}, year = {2026}, }




2025
-
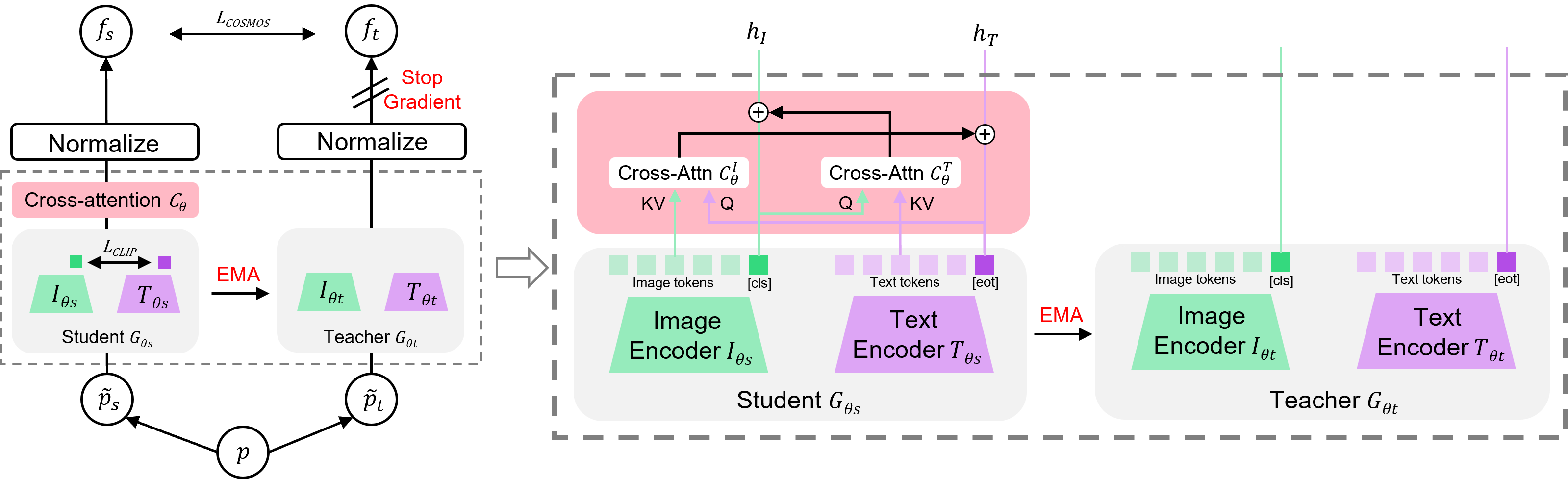 COSMOS: Cross-Modality Self-Distillation for Vision Language Pre-trainingSanghwan Kim, Rui Xiao, Mariana-Iuliana Georgescu, and 2 more authorsCVPR, 2025
COSMOS: Cross-Modality Self-Distillation for Vision Language Pre-trainingSanghwan Kim, Rui Xiao, Mariana-Iuliana Georgescu, and 2 more authorsCVPR, 2025Vision-Language Models (VLMs) trained with contrastive loss have achieved significant advancements in various vision and language tasks. However, the global nature of contrastive loss makes VLMs focus predominantly on foreground objects, neglecting other crucial information in the image, which limits their effectiveness in downstream tasks. To address these challenges, we propose COSMOS: CrOSs-MOdality Self-distillation for vision-language pre-training that integrates a novel text-cropping strategy and cross-attention module into a self-supervised learning framework. We create global and local views of images and texts (i.e., multi-modal augmentations), which are essential for self-distillation in VLMs. We further introduce a cross-attention module, enabling COSMOS to learn comprehensive cross-modal representations optimized via a cross-modality self-distillation loss. COSMOS consistently outperforms previous strong baselines on various zero-shot downstream tasks, including retrieval, classification, and semantic segmentation. Additionally, it surpasses CLIP-based models trained on larger datasets in visual perception and contextual understanding tasks.
@article{kim2024cosmos, title = {COSMOS: Cross-Modality Self-Distillation for Vision Language Pre-training}, author = {Kim, Sanghwan and Xiao, Rui and Georgescu, Mariana-Iuliana and Alaniz, Stephan and Akata, Zeynep}, journal = {CVPR}, year = {2025}, } -
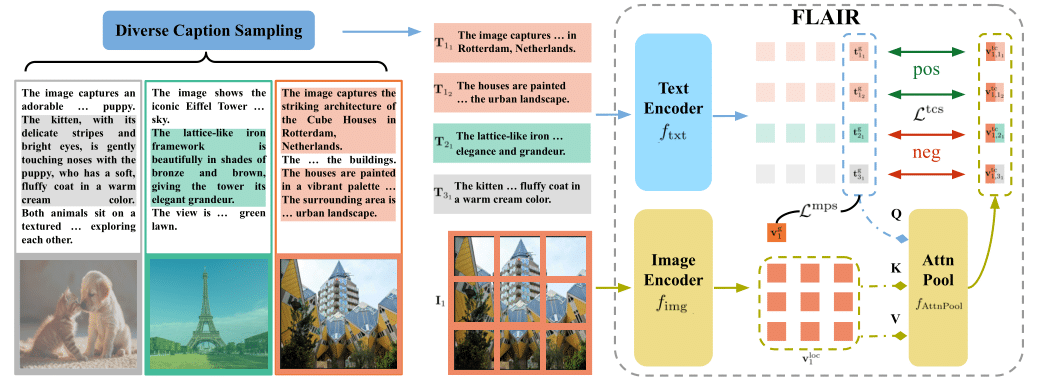 FLAIR: VLM with Fine-grained Language-informed Image RepresentationsRui Xiao, Sanghwan Kim, Mariana-Iuliana Georgescu, and 2 more authorsCVPR, 2025
FLAIR: VLM with Fine-grained Language-informed Image RepresentationsRui Xiao, Sanghwan Kim, Mariana-Iuliana Georgescu, and 2 more authorsCVPR, 2025CLIP has shown impressive results in aligning images and texts at scale. However, its ability to capture detailed visual features remains limited because CLIP matches images and texts at a global level. To address this issue, we propose FLAIR, Fine-grained Language-informed Image Representations, an approach that utilizes long and detailed image descriptions to learn localized image embeddings. By sampling diverse sub-captions that describe fine-grained details about an image, we train our vision-language model to produce not only global embeddings but also text-specific image representations. Our model introduces text-conditioned attention pooling on top of local image tokens to produce fine-grained image representations that excel at retrieving detailed image content. We achieve state-of-the-art performance on both, existing multimodal retrieval benchmarks, as well as, our newly introduced fine-grained retrieval task which evaluates vision-language models’ ability to retrieve partial image content. Furthermore, our experiments demonstrate the effectiveness of FLAIR trained on 30M image-text pairs in capturing fine-grained visual information, including zero-shot semantic segmentation, outperforming models trained on billions of pairs.
@article{xiao2024flair, title = {FLAIR: VLM with Fine-grained Language-informed Image Representations}, author = {Xiao, Rui and Kim, Sanghwan and Georgescu, Mariana-Iuliana and Akata, Zeynep and Alaniz, Stephan}, journal = {CVPR}, year = {2025}, }


2024
-
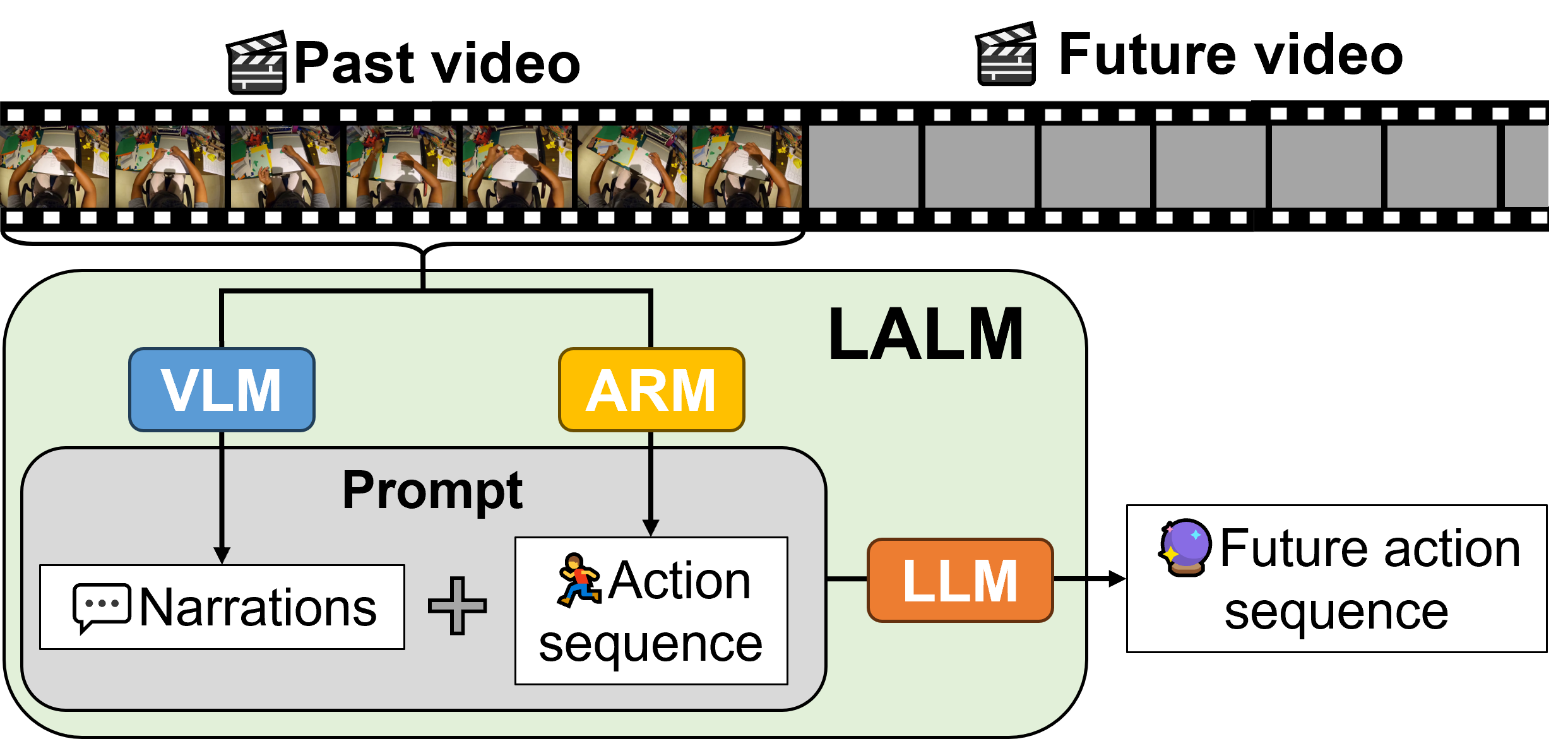 PALM: Predicting Actions through Language ModelsSanghwan Kim, Daoji Huang, Yongqin Xian, and 3 more authorsECCV, 2024
PALM: Predicting Actions through Language ModelsSanghwan Kim, Daoji Huang, Yongqin Xian, and 3 more authorsECCV, 2024Understanding human activity is a crucial yet intricate task in egocentric vision, a field that focuses on capturing visual perspectives from the camera wearer’s viewpoint. While traditional methods heavily rely on representation learning trained on extensive video data, there exists a significant limitation: obtaining effective video representations proves challenging due to the inherent complexity and variability in human activities.Furthermore, exclusive dependence on video-based learning may constrain a model’s capability to generalize across long-tail classes and out-of-distribution scenarios. In this study, we introduce a novel approach for long-term action anticipation using language models (LALM), adept at addressing the complex challenges of long-term activity understanding without the need for extensive training. Our method incorporates an action recognition model to track previous action sequences and a vision-language model to articulate relevant environmental details. By leveraging the context provided by these past events, we devise a prompting strategy for action anticipation using large language models (LLMs). Moreover, we implement Maximal Marginal Relevance for example selection to facilitate in-context learning of the LLMs. Our experimental results demonstrate that LALM surpasses the state-of-the-art methods in the task of long-term action anticipation on the Ego4D benchmark. We further validate LALM on two additional benchmarks, affirming its capacity for generalization across intricate activities with different sets of taxonomies. These are achieved without specific fine-tuning.
@article{kim2023lalm, title = {PALM: Predicting Actions through Language Models}, author = {Kim, Sanghwan and Huang, Daoji and Xian, Yongqin and Hilliges, Otmar and Van Gool, Luc and Wang, Xi}, journal = {ECCV}, year = {2024}, } -
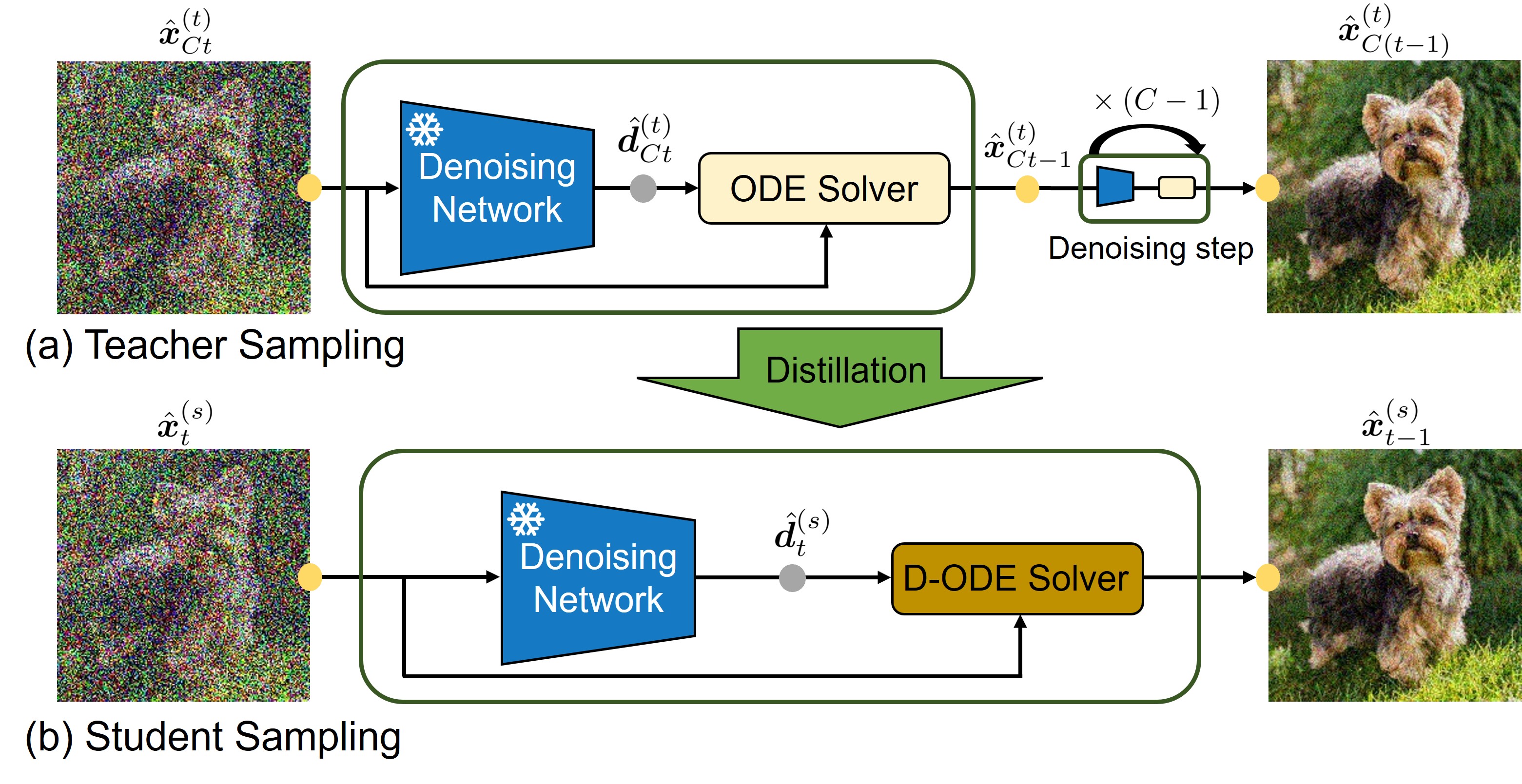 Distilling ODE Solvers of Diffusion Models into Smaller StepsSanghwan Kim, Hao Tang, and Fisher YuCVPR, 2024
Distilling ODE Solvers of Diffusion Models into Smaller StepsSanghwan Kim, Hao Tang, and Fisher YuCVPR, 2024Distillation techniques have substantially improved the sampling speed of diffusion models, allowing of the generation within only one step or a few steps. However, these distillation methods require extensive training for each dataset, sampler, and network, which limits their practical applicability. To address this limitation, we propose a straightforward distillation approach, Distilled-ODE solvers (D-ODE solvers), that optimizes the ODE solver rather than training the denoising network. D-ODE solvers are formulated by simply applying a single parameter adjustment to existing ODE solvers. Subsequently, D-ODE solvers with smaller steps are optimized by ODE solvers with larger steps through distillation over a batch of samples. Our comprehensive experiments indicate that D-ODE solvers outperform existing ODE solvers, including DDIM, PNDM, DPM-Solver, DEIS, and EDM, especially when generating samples with fewer steps. Our method incur negligible computational overhead compared to previous distillation techniques, enabling simple and rapid integration with previous samplers. Qualitative analysis further shows that D-ODE solvers enhance image quality while preserving the sampling trajectory of ODE solvers.
@article{kim2023distilling, title = {Distilling ODE Solvers of Diffusion Models into Smaller Steps}, author = {Kim, Sanghwan and Tang, Hao and Yu, Fisher}, journal = {CVPR}, year = {2024}, }


2023
-
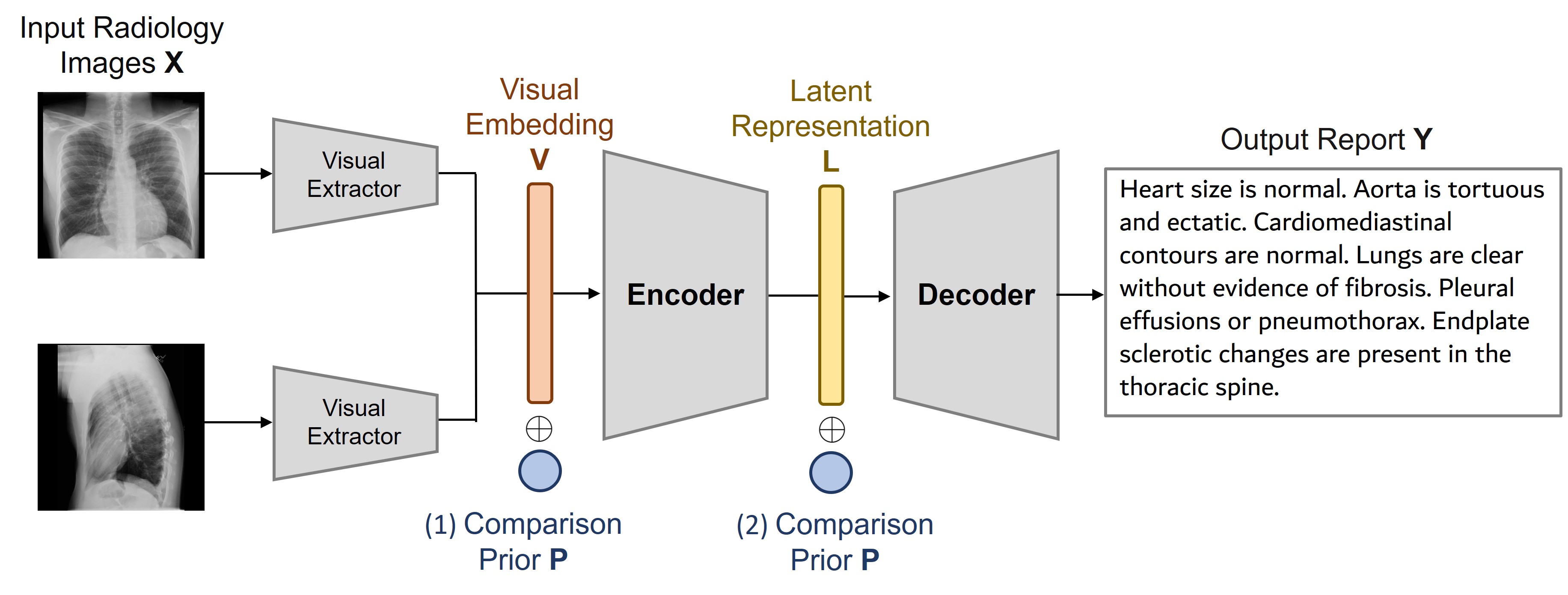 Boosting Radiology Report Generation by Infusing Comparison PriorSanghwan Kim, Farhad Nooralahzadeh, Morteza Rohanian, and 5 more authorsACL Workshop, 2023
Boosting Radiology Report Generation by Infusing Comparison PriorSanghwan Kim, Farhad Nooralahzadeh, Morteza Rohanian, and 5 more authorsACL Workshop, 2023Recent transformer-based models have made significant strides in generating radiology reports from chest X-ray images. However, a prominent challenge remains: these models often lack prior knowledge, resulting in the generation of synthetic reports that mistakenly reference non-existent prior exams. This discrepancy can be attributed to a knowledge gap between radiologists and the generation models. While radiologists possess patient-specific prior information, the models solely receive X-ray images at a specific time point. To tackle this issue, we propose a novel approach that leverages a rule-based labeler to extract comparison prior information from radiology reports. This extracted comparison prior is then seamlessly integrated into state-of-the-art transformer-based models, enabling them to produce more realistic and comprehensive reports. Our method is evaluated on English report datasets, such as IU X-ray and MIMIC-CXR. The results demonstrate that our approach surpasses baseline models in terms of natural language generation metrics. Notably, our model generates reports that are free from false references to non-existent prior exams, setting it apart from previous models. By addressing this limitation, our approach represents a significant step towards bridging the gap between radiologists and generation models in the domain of medical report generation.
@article{kim2023boosting, title = {Boosting Radiology Report Generation by Infusing Comparison Prior}, author = {Kim, Sanghwan and Nooralahzadeh, Farhad and Rohanian, Morteza and Fujimoto, Koji and Nishio, Mizuho and Sakamoto, Ryo and Rinaldi, Fabio and Krauthammer, Michael}, journal = {ACL Workshop}, year = {2023}, } -
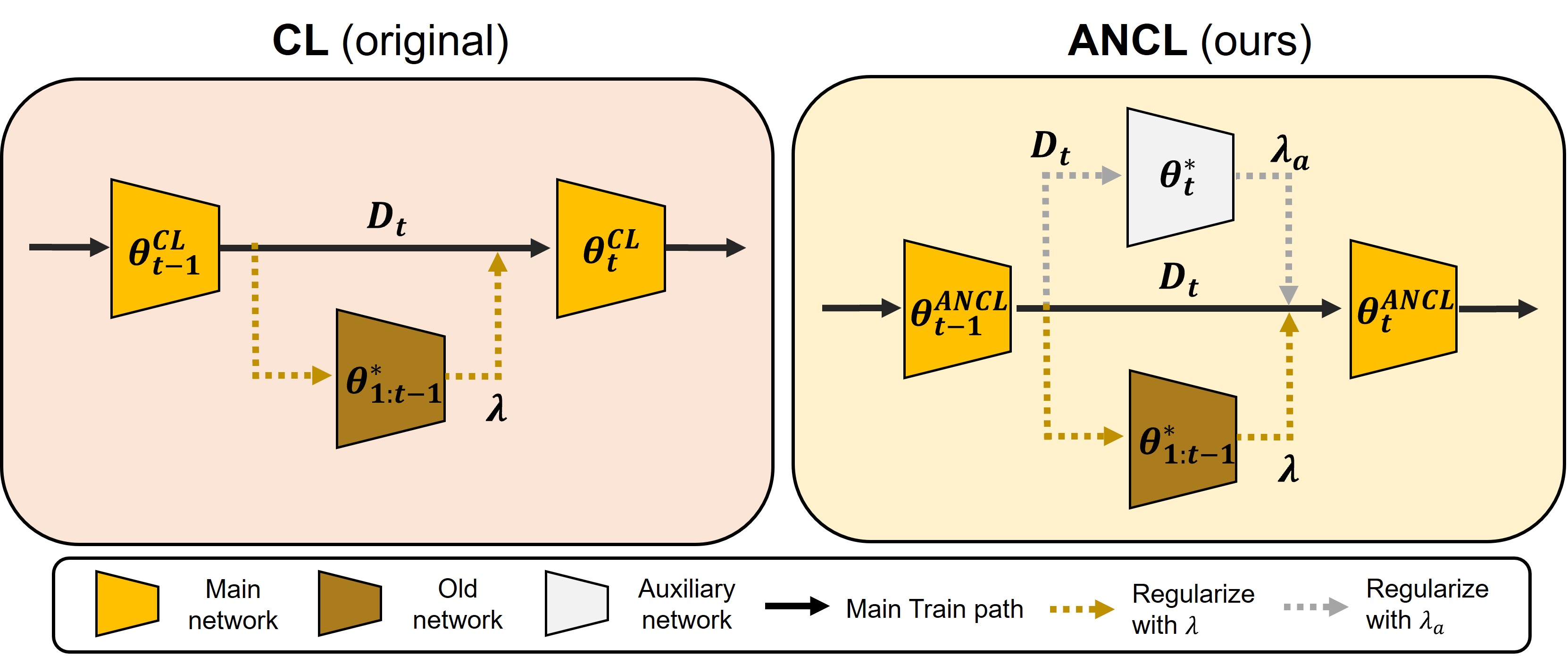 Achieving a Better Stability-Plasticity Trade-off via Auxiliary Networks in Continual LearningSanghwan Kim, Lorenzo Noci, Antonio Orvieto, and 1 more authorCVPR, 2023
Achieving a Better Stability-Plasticity Trade-off via Auxiliary Networks in Continual LearningSanghwan Kim, Lorenzo Noci, Antonio Orvieto, and 1 more authorCVPR, 2023In contrast to the natural capabilities of humans to learn new tasks in a sequential fashion, neural networks are known to suffer from catastrophic forgetting, where the model’s performances on old tasks drop dramatically after being optimized for a new task. Since then, the continual learning (CL) community has proposed several solutions aiming to equip the neural network with the ability to learn the current task (plasticity) while still achieving high accuracy on the previous tasks (stability). Despite remarkable improvements, the plasticity-stability trade-off is still far from being solved and its underlying mechanism is poorly understood. In this work, we propose Auxiliary Network Continual Learning (ANCL), a novel method that applies an additional auxiliary network which promotes plasticity to the continually learned model which mainly focuses on stability. More concretely, the proposed framework materializes in a regularizer that naturally interpolates between plasticity and stability, surpassing strong baselines on task incremental and class incremental scenarios. Through extensive analyses on ANCL solutions, we identify some essential principles beneath the stability-plasticity trade-off.
@article{kim2023achieving, title = {Achieving a Better Stability-Plasticity Trade-off via Auxiliary Networks in Continual Learning}, author = {Kim, Sanghwan and Noci, Lorenzo and Orvieto, Antonio and Hofmann, Thomas}, journal = {CVPR}, year = {2023}, }


2020
-
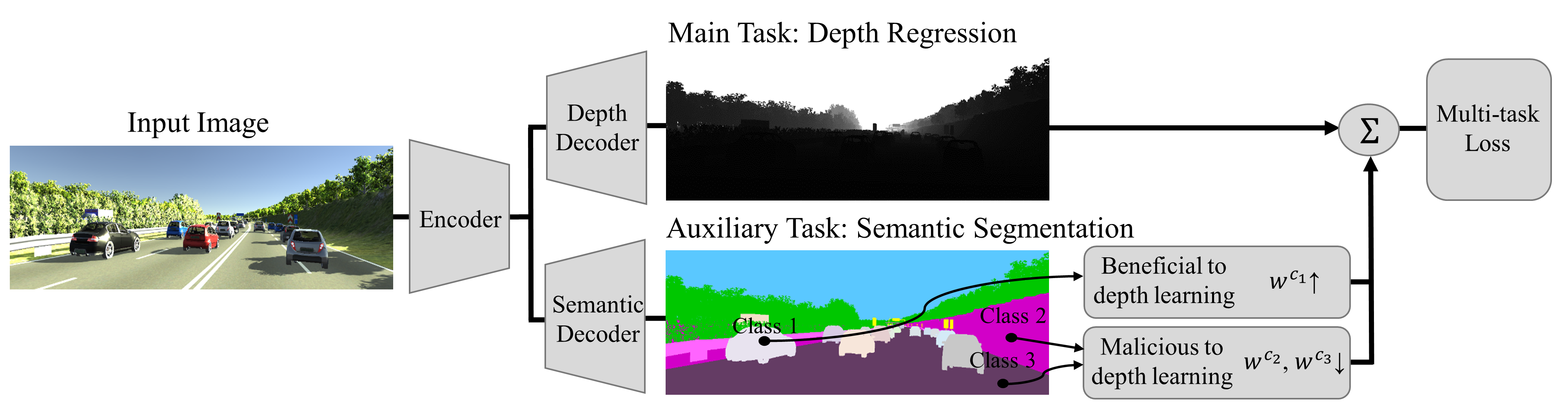 Learning Boost by Exploiting the Auxiliary Task in Multi-task DomainJonghwa Yim, and Sanghwan KimarXiv preprint arXiv:2008.02043, 2020
Learning Boost by Exploiting the Auxiliary Task in Multi-task DomainJonghwa Yim, and Sanghwan KimarXiv preprint arXiv:2008.02043, 2020Learning two tasks in a single shared function has some benefits. Firstly by acquiring information from the second task, the shared function leverages useful information that could have been neglected or underestimated in the first task. Secondly, it helps to generalize the function that can be learned using generally applicable information for both tasks. To fully enjoy these benefits, Multi-task Learning (MTL) has long been researched in various domains such as computer vision, language understanding, and speech synthesis. While MTL benefits from the positive transfer of information from multiple tasks, in a real environment, tasks inevitably have a conflict between them during the learning phase, called negative transfer. The negative transfer hampers function from achieving the optimality and degrades the performance. To solve the problem of the task conflict, previous works only suggested partial solutions that are not fundamental, but ad-hoc. A common approach is using a weighted sum of losses. The weights are adjusted to induce positive transfer. Paradoxically, this kind of solution acknowledges the problem of negative transfer and cannot remove it unless the weight of the task is set to zero. Therefore, these previous methods had limited success. In this paper, we introduce a novel approach that can drive positive transfer and suppress negative transfer by leveraging class-wise weights in the learning process. The weights act as an arbitrator of the fundamental unit of information to determine its positive or negative status to the main task.
@article{yim2020learning, title = {Learning Boost by Exploiting the Auxiliary Task in Multi-task Domain}, author = {Yim, Jonghwa and Kim, Sanghwan}, journal = {arXiv preprint arXiv:2008.02043}, year = {2020}, }
