Sanghwan Kim

Munich, Germany
I am an ELLIS PhD Student co-advised by Zeynep Akata (TUM & Helmholtz Munich) and Yongqin Xian (Google Zurich). I hold a Master’s degree in Data Science from ETH Zurich and a Bachelor’s degree in Electrical Engineering from KAIST.
My research focuses on machine perception, particularly at the intersection of computer vision and natural language processing. Currently, I am working on vision-language pre-training and video question answering.
I’m always open to collaborations or project supervisions! Feel free to reach out :).
Selected publications
2024
-
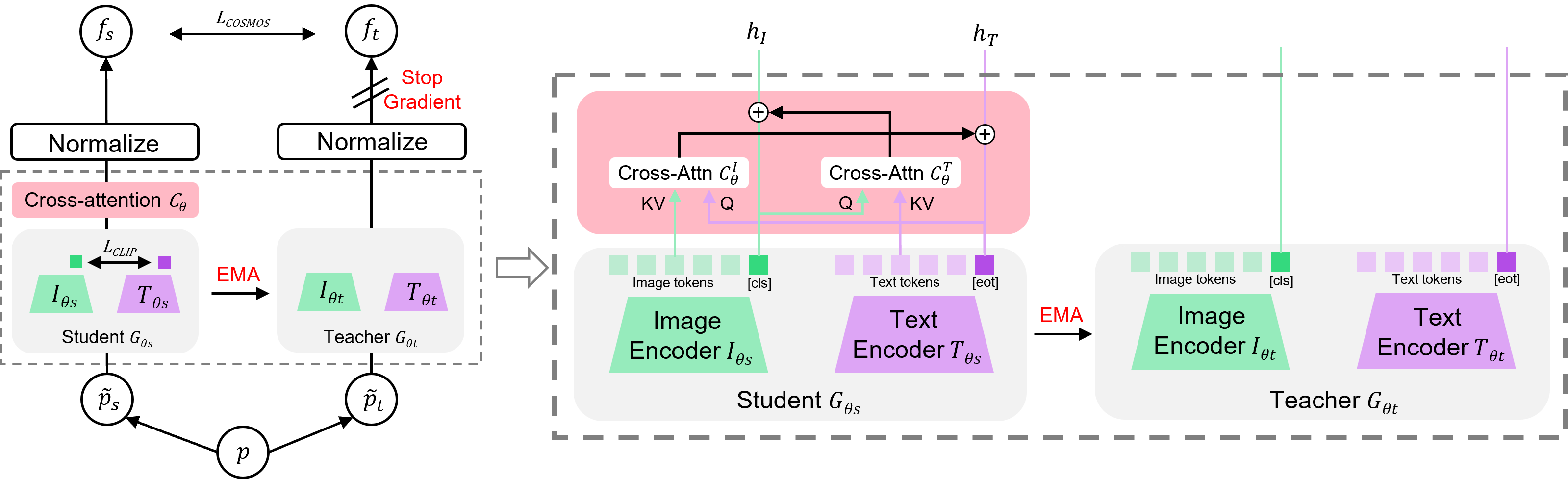 COSMOS: Cross-Modality Self-Distillation for Vision Language Pre-trainingSanghwan Kim, Rui Xiao, Mariana-Iuliana Georgescu, and 2 more authorsarXiv preprint arXiv:2412.01814, 2024
COSMOS: Cross-Modality Self-Distillation for Vision Language Pre-trainingSanghwan Kim, Rui Xiao, Mariana-Iuliana Georgescu, and 2 more authorsarXiv preprint arXiv:2412.01814, 2024Vision-Language Models (VLMs) trained with contrastive loss have achieved significant advancements in various vision and language tasks. However, the global nature of contrastive loss makes VLMs focus predominantly on foreground objects, neglecting other crucial information in the image, which limits their effectiveness in downstream tasks. To address these challenges, we propose COSMOS: CrOSs-MOdality Self-distillation for vision-language pre-training that integrates a novel text-cropping strategy and cross-attention module into a self-supervised learning framework. We create global and local views of images and texts (i.e., multi-modal augmentations), which are essential for self-distillation in VLMs. We further introduce a cross-attention module, enabling COSMOS to learn comprehensive cross-modal representations optimized via a cross-modality self-distillation loss. COSMOS consistently outperforms previous strong baselines on various zero-shot downstream tasks, including retrieval, classification, and semantic segmentation. Additionally, it surpasses CLIP-based models trained on larger datasets in visual perception and contextual understanding tasks.
@article{kim2024cosmos, title = {COSMOS: Cross-Modality Self-Distillation for Vision Language Pre-training}, author = {Kim, Sanghwan and Xiao, Rui and Georgescu, Mariana-Iuliana and Alaniz, Stephan and Akata, Zeynep}, journal = {arXiv preprint arXiv:2412.01814}, year = {2024}, } -
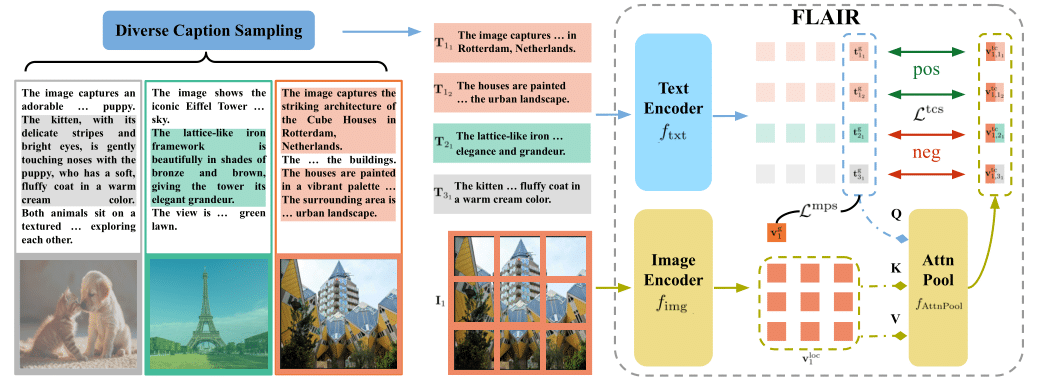 FLAIR: VLM with Fine-grained Language-informed Image RepresentationsRui Xiao, Sanghwan Kim, Mariana-Iuliana Georgescu, and 2 more authorsarXiv preprint arXiv:2412.03561, 2024
FLAIR: VLM with Fine-grained Language-informed Image RepresentationsRui Xiao, Sanghwan Kim, Mariana-Iuliana Georgescu, and 2 more authorsarXiv preprint arXiv:2412.03561, 2024CLIP has shown impressive results in aligning images and texts at scale. However, its ability to capture detailed visual features remains limited because CLIP matches images and texts at a global level. To address this issue, we propose FLAIR, Fine-grained Language-informed Image Representations, an approach that utilizes long and detailed image descriptions to learn localized image embeddings. By sampling diverse sub-captions that describe fine-grained details about an image, we train our vision-language model to produce not only global embeddings but also text-specific image representations. Our model introduces text-conditioned attention pooling on top of local image tokens to produce fine-grained image representations that excel at retrieving detailed image content. We achieve state-of-the-art performance on both, existing multimodal retrieval benchmarks, as well as, our newly introduced fine-grained retrieval task which evaluates vision-language models’ ability to retrieve partial image content. Furthermore, our experiments demonstrate the effectiveness of FLAIR trained on 30M image-text pairs in capturing fine-grained visual information, including zero-shot semantic segmentation, outperforming models trained on billions of pairs.
@article{xiao2024flair, title = {FLAIR: VLM with Fine-grained Language-informed Image Representations}, author = {Xiao, Rui and Kim, Sanghwan and Georgescu, Mariana-Iuliana and Akata, Zeynep and Alaniz, Stephan}, journal = {arXiv preprint arXiv:2412.03561}, year = {2024}, } -
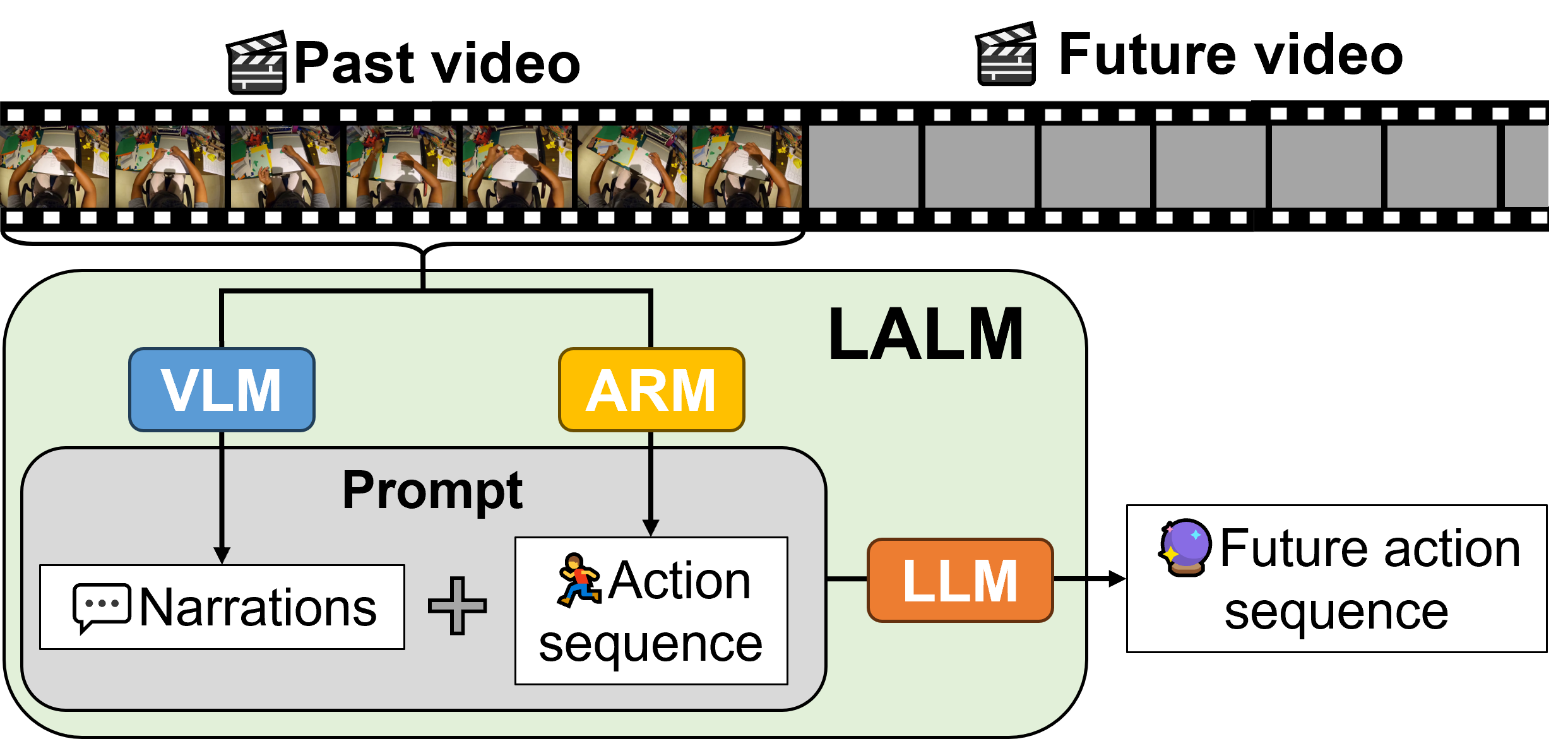 PALM: Predicting Actions through Language ModelsSanghwan Kim, Daoji Huang, Yongqin Xian, and 3 more authorsECCV, 2024
PALM: Predicting Actions through Language ModelsSanghwan Kim, Daoji Huang, Yongqin Xian, and 3 more authorsECCV, 2024Understanding human activity is a crucial yet intricate task in egocentric vision, a field that focuses on capturing visual perspectives from the camera wearer’s viewpoint. While traditional methods heavily rely on representation learning trained on extensive video data, there exists a significant limitation: obtaining effective video representations proves challenging due to the inherent complexity and variability in human activities.Furthermore, exclusive dependence on video-based learning may constrain a model’s capability to generalize across long-tail classes and out-of-distribution scenarios. In this study, we introduce a novel approach for long-term action anticipation using language models (LALM), adept at addressing the complex challenges of long-term activity understanding without the need for extensive training. Our method incorporates an action recognition model to track previous action sequences and a vision-language model to articulate relevant environmental details. By leveraging the context provided by these past events, we devise a prompting strategy for action anticipation using large language models (LLMs). Moreover, we implement Maximal Marginal Relevance for example selection to facilitate in-context learning of the LLMs. Our experimental results demonstrate that LALM surpasses the state-of-the-art methods in the task of long-term action anticipation on the Ego4D benchmark. We further validate LALM on two additional benchmarks, affirming its capacity for generalization across intricate activities with different sets of taxonomies. These are achieved without specific fine-tuning.
@article{kim2023lalm, title = {PALM: Predicting Actions through Language Models}, author = {Kim, Sanghwan and Huang, Daoji and Xian, Yongqin and Hilliges, Otmar and Van Gool, Luc and Wang, Xi}, journal = {ECCV}, year = {2024}, } -
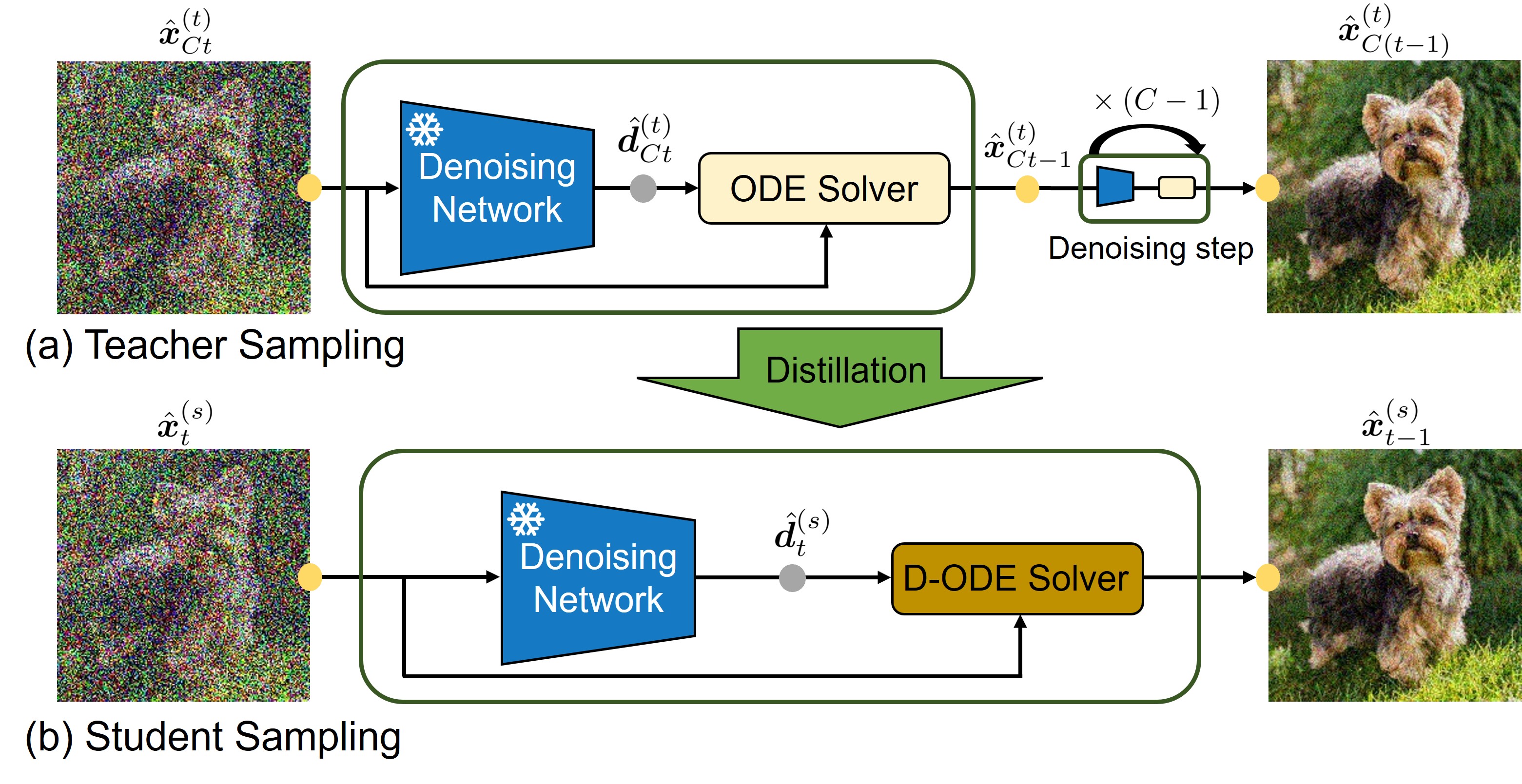 Distilling ODE Solvers of Diffusion Models into Smaller StepsSanghwan Kim, Hao Tang, and Fisher YuCVPR, 2024
Distilling ODE Solvers of Diffusion Models into Smaller StepsSanghwan Kim, Hao Tang, and Fisher YuCVPR, 2024Distillation techniques have substantially improved the sampling speed of diffusion models, allowing of the generation within only one step or a few steps. However, these distillation methods require extensive training for each dataset, sampler, and network, which limits their practical applicability. To address this limitation, we propose a straightforward distillation approach, Distilled-ODE solvers (D-ODE solvers), that optimizes the ODE solver rather than training the denoising network. D-ODE solvers are formulated by simply applying a single parameter adjustment to existing ODE solvers. Subsequently, D-ODE solvers with smaller steps are optimized by ODE solvers with larger steps through distillation over a batch of samples. Our comprehensive experiments indicate that D-ODE solvers outperform existing ODE solvers, including DDIM, PNDM, DPM-Solver, DEIS, and EDM, especially when generating samples with fewer steps. Our method incur negligible computational overhead compared to previous distillation techniques, enabling simple and rapid integration with previous samplers. Qualitative analysis further shows that D-ODE solvers enhance image quality while preserving the sampling trajectory of ODE solvers.
@article{kim2023distilling, title = {Distilling ODE Solvers of Diffusion Models into Smaller Steps}, author = {Kim, Sanghwan and Tang, Hao and Yu, Fisher}, journal = {CVPR}, year = {2024}, }




2023
-
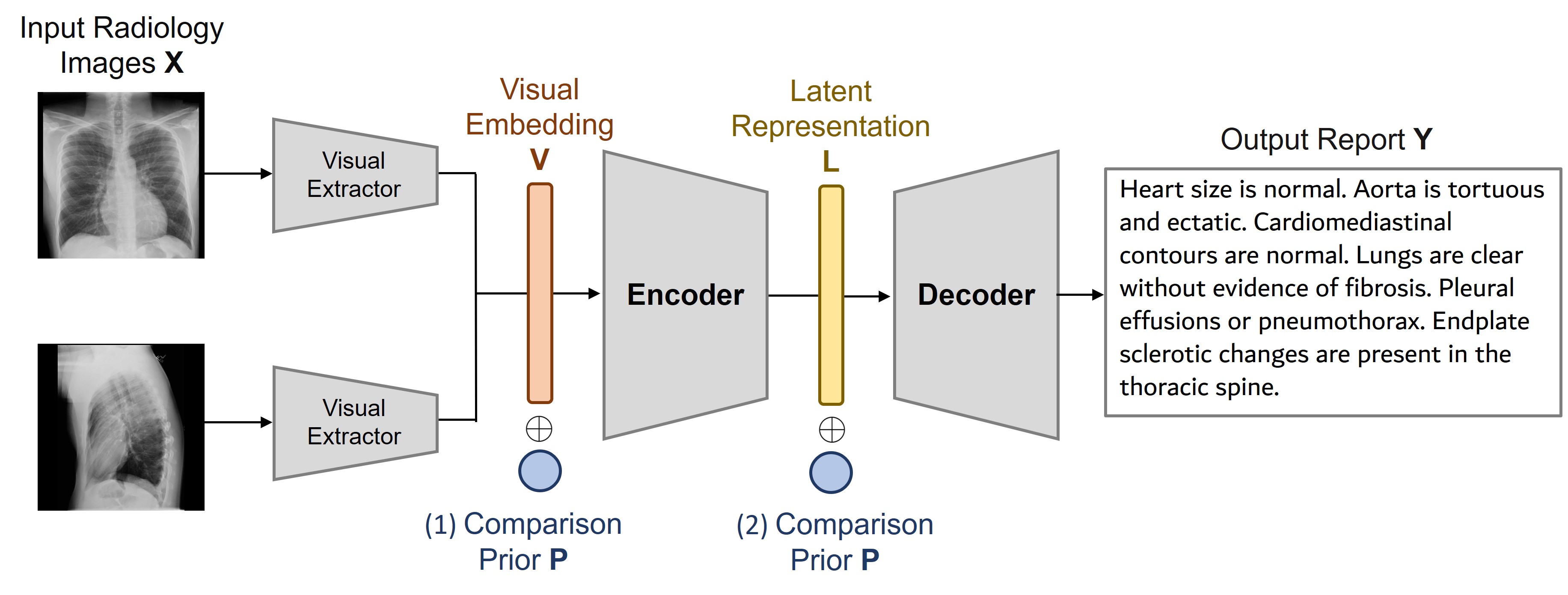 Boosting Radiology Report Generation by Infusing Comparison PriorSanghwan Kim, Farhad Nooralahzadeh, Morteza Rohanian, and 5 more authorsACL Workshop, 2023
Boosting Radiology Report Generation by Infusing Comparison PriorSanghwan Kim, Farhad Nooralahzadeh, Morteza Rohanian, and 5 more authorsACL Workshop, 2023Recent transformer-based models have made significant strides in generating radiology reports from chest X-ray images. However, a prominent challenge remains: these models often lack prior knowledge, resulting in the generation of synthetic reports that mistakenly reference non-existent prior exams. This discrepancy can be attributed to a knowledge gap between radiologists and the generation models. While radiologists possess patient-specific prior information, the models solely receive X-ray images at a specific time point. To tackle this issue, we propose a novel approach that leverages a rule-based labeler to extract comparison prior information from radiology reports. This extracted comparison prior is then seamlessly integrated into state-of-the-art transformer-based models, enabling them to produce more realistic and comprehensive reports. Our method is evaluated on English report datasets, such as IU X-ray and MIMIC-CXR. The results demonstrate that our approach surpasses baseline models in terms of natural language generation metrics. Notably, our model generates reports that are free from false references to non-existent prior exams, setting it apart from previous models. By addressing this limitation, our approach represents a significant step towards bridging the gap between radiologists and generation models in the domain of medical report generation.
@article{kim2023boosting, title = {Boosting Radiology Report Generation by Infusing Comparison Prior}, author = {Kim, Sanghwan and Nooralahzadeh, Farhad and Rohanian, Morteza and Fujimoto, Koji and Nishio, Mizuho and Sakamoto, Ryo and Rinaldi, Fabio and Krauthammer, Michael}, journal = {ACL Workshop}, year = {2023}, } -
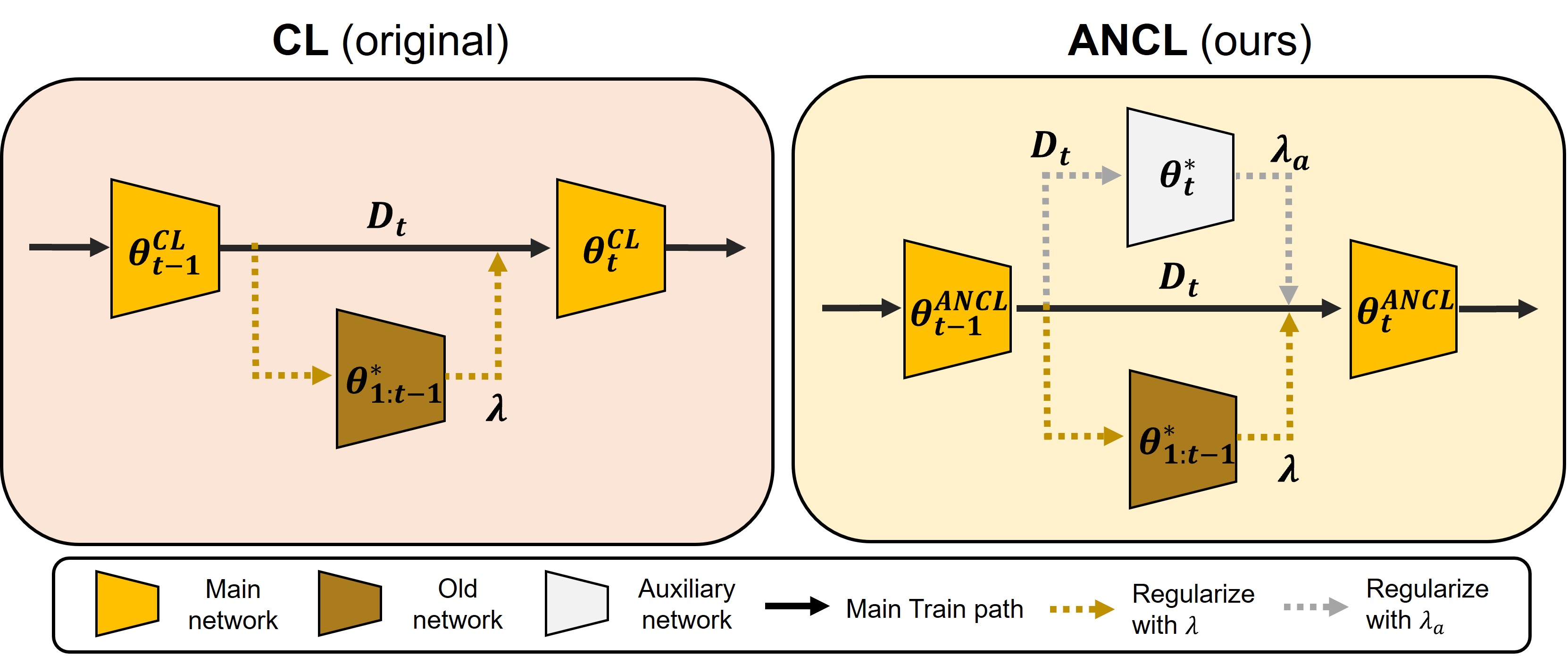 Achieving a Better Stability-Plasticity Trade-off via Auxiliary Networks in Continual LearningSanghwan Kim, Lorenzo Noci, Antonio Orvieto, and 1 more authorCVPR, 2023
Achieving a Better Stability-Plasticity Trade-off via Auxiliary Networks in Continual LearningSanghwan Kim, Lorenzo Noci, Antonio Orvieto, and 1 more authorCVPR, 2023In contrast to the natural capabilities of humans to learn new tasks in a sequential fashion, neural networks are known to suffer from catastrophic forgetting, where the model’s performances on old tasks drop dramatically after being optimized for a new task. Since then, the continual learning (CL) community has proposed several solutions aiming to equip the neural network with the ability to learn the current task (plasticity) while still achieving high accuracy on the previous tasks (stability). Despite remarkable improvements, the plasticity-stability trade-off is still far from being solved and its underlying mechanism is poorly understood. In this work, we propose Auxiliary Network Continual Learning (ANCL), a novel method that applies an additional auxiliary network which promotes plasticity to the continually learned model which mainly focuses on stability. More concretely, the proposed framework materializes in a regularizer that naturally interpolates between plasticity and stability, surpassing strong baselines on task incremental and class incremental scenarios. Through extensive analyses on ANCL solutions, we identify some essential principles beneath the stability-plasticity trade-off.
@article{kim2023achieving, title = {Achieving a Better Stability-Plasticity Trade-off via Auxiliary Networks in Continual Learning}, author = {Kim, Sanghwan and Noci, Lorenzo and Orvieto, Antonio and Hofmann, Thomas}, journal = {CVPR}, year = {2023}, }

